
Die Themen BPMN und KI sind derzeit in aller Munde. Da liegt es nahe, darüber nachzudenken, welche Potenziale sich durch die Verbindung der beiden Themen ergeben können. Und genau hier setzt bpmn.ai an. Es geht dabei zum einen darum, mit dem Einsatz von Machine Learning Algorithmen nützliche Informationen aus den Daten zu gewinnen, die durch die Ausführung von Geschäftsprozessen entstehen. Zum anderen geht es darum zu schauen, wie diese gewonnenen Informationen zur Optimierung und Automatisierung der Geschäftsprozesse genutzt werden können.
Wie wir diese Fragestellung in der viadee verfolgen und was mich dabei in meinen ersten Monaten bei der viadee umgetrieben hat, darüber berichte ich in diesem Blogpost.
Bevor ich bei der viadee eingestiegen bin, waren für mich die beiden Themen BPMN (Business Process Model and Notation) und KI immer von hohem persönlichen Interesse. Dass ich mich zum Einstieg genau mit dieser Kombination beschäftigen durfte, war für mich eine sehr erfreuliche Überraschung und ich wusste ziemlich schnell, dass ich dieses Thema auch langfristig neben meinen Kundenprojekten betreuen möchte.
Die bpmn.ai Idee
Bei der Ausführung von Geschäftsprozessen fallen eine Reihe von Daten an, wie z. B.- die Dauer eines kompletten Prozessdurchlaufs, aber auch die von einzelnen Prozessschritten;
- die Fallentscheidungen, die im Rahmen eines Prozessdurchlaufs getroffen werden;
- die Werte von Variablen im Prozess und deren Veränderung im Laufe eines Prozessdurchlaufs.

BPMN steht für Business Process Model and Notation und ist ein etablierter globaler Standard zur Modellierung von Geschäftsprozessen. Er findet heute vor allem bei der Nutzung von Process Engines Anwendung, um die Geschäftsprozesse nicht nur zu modellieren, sondern diese auch zum Leben zu erwecken. Zu den bekanntesten und beliebtesten Process Engines zählt Camunda BPM. Sie erlaubt die systemgestützte Ausführung von Geschäftsprozessen, die in BPMN modelliert wurden.
Die bpmn.ai Pipeline
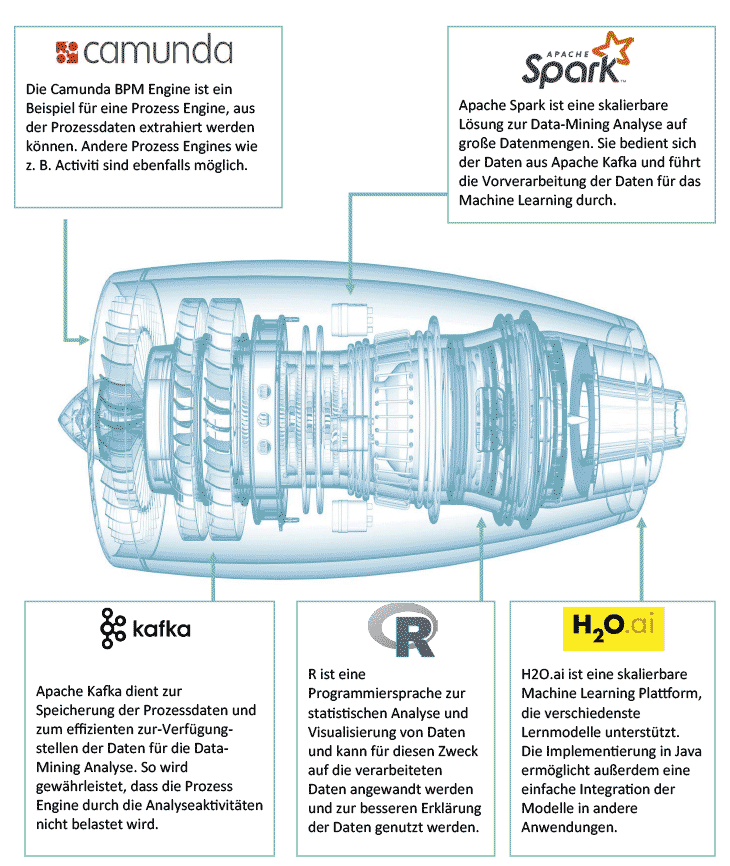 Die Grafik zeigt die bpmn.ai Pipeline und die dafür eingesetzten Technologien. Generell setzen wir bei bpmn.ai (mit Ausnahme der Datenexploration mit R) auf Java Technologien , da wir hier zum einen ein hohes Maß an interner Kompetenz besitzen. Zum anderen erlaubt uns dies den skalierbaren Einsatz von bpmn.ai auf verschiedensten Plattformen.
Die Grafik zeigt die bpmn.ai Pipeline und die dafür eingesetzten Technologien. Generell setzen wir bei bpmn.ai (mit Ausnahme der Datenexploration mit R) auf Java Technologien , da wir hier zum einen ein hohes Maß an interner Kompetenz besitzen. Zum anderen erlaubt uns dies den skalierbaren Einsatz von bpmn.ai auf verschiedensten Plattformen.
Im ersten Schritt unterstützen wir die Process Engine Camunda. Generell kann bpmn.ai mit wenig Aufwand erweitert werden, sodass es auch für andere Process Engines zum Einsatz kommen kann. Die gemeinsame Java Basis von Camunda und bpmn.ai erlaubt uns außerdem eine einfache Extraktion von Prozessdaten, die in Java-Objekten gekapselt sind.
Die Datenextraktion aus der Process Engine und Datenarchivierung erfolgt mithilfe der OpenSource Streaming Plattform Apache Kafka. Sie erlaubt das effiziente Verarbeiten von Datenströmen und bietet dazu Schnittstellen zum effizienten Laden und Speichern dieser an.
In Camunda haben wir ein History Listener Plugin implementiert, welches die anfallenden Prozessdaten im laufenden Betrieb in Kafka Queues schreibt, sodass wir die Datenbank von Camunda bei der Verarbeitung der Daten in bpmn.ai nicht mit großen Anfragen belasten müssen, sondern hier über parallele Zugriffe auf die verschiedenen Topics in Kafka setzen können.
Bei der Vorverarbeitung der Daten setzen wir auf die OpenSource-Software Apache Spark. Es erlaubt die effiziente parallele Verarbeitung von großen Datenmengen auf Clustern und eignet sich damit optimal für den Einsatz in der Vorverarbeitung. Diese Einschätzung hat sich im Laufe der Entwicklung bestätigt, da wir dadurch mit bpmn.ai Operationen in wenigen Minuten durchführen können, die unsere Kunden mit normalen Datenbank-Bordmitteln nicht sinnvoll umsetzen konnten. Insbesondere das Zusammentragen von Prozessvariablen über Prozessschritte hinweg verdient hier besondere Aufmerksamkeit. Hier gibt es kein Join-Kriterium, mit dem sich der Wissensstand des Prozesses zu einem Wunsch-Zeitpunkt rekonstruieren ließe – dies ist mit relationalen Mitteln nicht auszudrücken. Sauber zu rekonstruieren „Was wusste ich wann?“, ist für Prognosemodelle aber essenziell wichtig.
Die anschließende explorative Analyse der Daten erfolgt mithilfe von R. Die Programmiersprache ist für statistische Analysen und Auswertungen sehr verbreitet und etabliert und besitzt dazu die Möglichkeit, direkt auf Daten in Apache Spark zuzugreifen.
Das Machine Learning erfolgt schließlich durch H2O, einer ebenfalls Java-basierten OpenSource-Software , deren Einsatzgebiet insbesondere das Machine Learning ist. Es bietet Schnittstellen für Apache Spark und R und passt damit optimal in unseren Technologie Stack.
Generell kann bpmn.ai die Prozessdaten in zwei verschiedene Aggregationslevel verdichten. Zum einen in die Ebene der Prozessinstanzen. Dabei werden die Daten so verdichtet, dass für jede Prozessinstanz (jeden Durchlauf eines Prozesses) der Wissensstand zum Ende des Prozesses ermittelt wird. Dies wird zum Beispiel genutzt, um Vorhersagen zu Prozesslaufzeiten machen zu können.
Zum anderen gibt es die Ebene der Aktivitätsinstanzen. Hierbei ist für eine Prozessinstanz der Wissensstand nach jeder durchlaufenen Aktivität (zum Beispiel „Rechnung sichten“ aus dem unten dargestellten Beispielprozess) in dieser Prozessinstanz ermittelbar. Damit lassen sich z. B. Machine Learning Algorithmen anlernen, die Aussagen zu bestimmten Aktivitäten in Prozessen machen, wie z. B. die Entscheidung bzgl. des nächsten Prozessschrittes bei einer Verzweigung (zum Beispiel „externe Rechnungsprüfung notwendig?“).
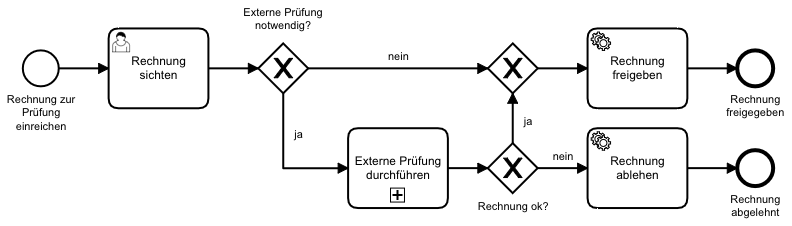
Beide Ebenen haben wir bereits mit unseren Kunden Duni und Provinzial erprobt und damit zur Verbesserung derer Prozessabläufe beitragen können.
Erfahrungen mit Apache Spark
Generell sind meine Erfahrungen mit Apache Spark durchaus positiv. Es nimmt einem sehr viel ab, wenn es um die Optimierung hinsichtlich Parallelität und Clusterbetrieb geht. Aber auch diese Optimierung hat natürlich Grenzen. Während die Optimierung allgemein sehr gut funktioniert, ist ständig zu hinterfragen, ob der gewählte Ansatz generell der effizienteste für das vorliegende Problem ist. So gab es Situationen, in denen die offensichtliche Implementierung einer Datentransformation zu einer Laufzeit von mehreren Stunden führte, die Wahl eines anderen Ansatzes dagegen zu einer Laufzeit von wenigen Minuten. Es ist daher empfehlenswert, die internen Mechanismen von Apache Spark zu kennen und zu verstehen und gewählte Ansätze nochmal infrage zu stellen, z. B. wenn einem die Laufzeit auffällig hoch erscheint.Eine Sache, an die man sich bei der Entwicklung von Apache Spark Applikationen gewöhnen muss, ist, dass man über die API lediglich den Bauplan der Datentransformation für Spark implementiert – analog zu SQL. Die Ausführung der Schritte erfolgt dann später innerhalb von Spark in der als optimal ermittelten Reihenfolge und, wo möglich, auch parallel und ist damit nicht mit der Reihenfolge, wie sie im Code geschrieben wurde, identisch. Daher geht z. B. das Speichern von Zwischenwerten in Java Variablen ohne die Verwendung der von Spark zur Verfügung gestellten Mittel, wie z. B. Broadcast Variablen, so gut wie immer schief. Nach einer gewissen Eingewöhnungszeit hat man diese Mechanismen aber verinnerlicht.
Ein weiterer Punkt ist die gewählte Sprache, in der man Spark Anwendungen entwickelt: Spark selbst ist in Scala implementiert, einer objektorientierten Sprache mit starken funktionalen Elementen. Es werden jedoch weitere APIs für Java, Python, SQL und R bereitgestellt, sodass man Spark Applikationen in verschiedenen Sprachen entwickeln kann.
Aufgrund unserer Expertise im Bereich Java und weil andere für bpmn.ai gewählte Technologien ebenfalls auf Java basieren, haben wir uns für die Entwicklung in Java entschieden. Dies funktioniert generell recht gut, es gibt jedoch einige Punkte, die die Entwicklung zumindest zu Beginn verzögern und an denen man merkt, dass man nicht in der nativen Sprache von Spark unterwegs ist. Zum Beispiel tritt der Effekt auf, dass wenn eine Transformation über eine anonyme Implementierung des entsprechenden Spark Interfaces umgesetzt wird, bei der Ausführung der Spark Applikation ein Serialisierungsfehler auftritt. Wandelt man die anonyme Implementierung jedoch in einen Lambda Ausdruck um, funktioniert es einwandfrei. Auch wenn man nach möglichen Lösungen für die beste Umsetzung in Spark sucht, findet man in den meisten Fällen Code-Beispiele in Scala und muss diese dann in die korrekte Java API übersetzen. Generell fand ich es sehr hilfreich, die erforderlichen Transformationsschritte zunächst in einem Spark-Notebook , wie z. B. mit Apache Zeppelin (in Scala) zu implementieren und dann den fertigen Code in die Java Anwendung zu übersetzen. Die Nutzung von Apache Zeppelin oder einem alternativen Spark Notebook würde ich auch empfehlen, wenn man direkt in Scala implementiert, da man damit sehr gut größere Datentransformationen schrittweise entwickeln kann.
bpmn.ai ist OpenSource
Wir haben uns in der viadee dazu entschieden, die Grundfunktionalität von bpmn.ai als OpenSource-Anwendung zur Verfügung zu stellen.
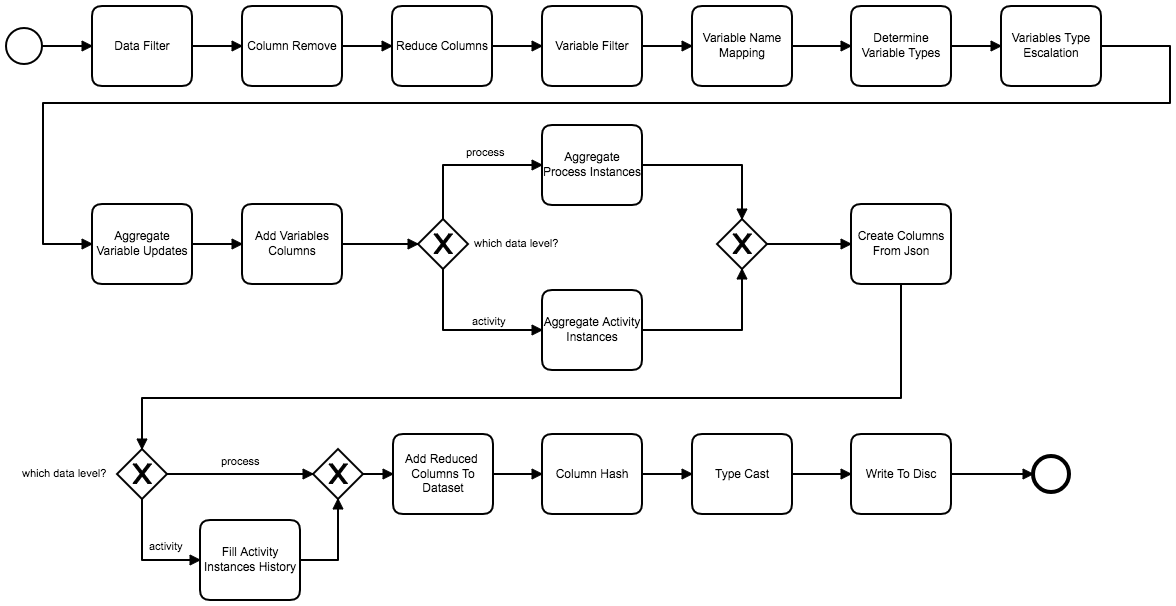
Konkret sind dies die konfigurierbaren Apache Spark Anwendungen , die die Vorverarbeitung der Daten übernehmen. Die Anwendungen erlauben die Extrahierung der Daten aus einer Apache Kafka Instanz und die anschließende Vorverarbeitung, sodass darauf ein Machine Learning Algorithmus angelernt werden kann. Die Pipeline zur Transformation der Daten kann dabei frei konfiguriert, angepasst und erweitert werden, um sie an den gegebenen Anwendungsfall anzupassen. So können neue Transformationsschritte über die Implementierung eines einfachen Interfaces implementiert werden. Sie sind dann ebenso einfach per Konfiguration in die Pipeline zu integrieren.
Die im OpenSource-Projekt vorhandene Pipeline ist in der folgenden Abbildung zu sehen – viele typische Anwendungsfälle sind enthalten und einer schnellen Proberunde mit den eigenen Daten steht nichts im Wege.
Wer sich an der Entwicklung von bpmn.ai beteiligen möchte, kann dies gerne über Github machen oder sich auch bzgl. einer Zusammenarbeit direkt an die viadee wenden.
Quellcode und weitere Details zu bpmn.ai gibt es unter [ github ].
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



