
Von viadee entwickelter Prototyp zeigt gute Ergebnisse bei der automatischen Identifizierung von Interaktionselementen anhand von Screenshots.
„Vervollständige Eingabemaske!“ – so oder so ähnlich wünschen sich Anwender die Arbeit mit ihren Test-Frameworks zur Steuerung von Benutzeroberflächen. Weg von inkrementellen, detaillierten und technischen Spezifikationen hin zu einfachen und intelligenten Systemen. Lässt sich ein solches System bereits umsetzen oder ist das alles noch Zukunftsmusik? Mögliche Lösungsansätze bieten Computer Vision (CV) und Machine Learning (ML).


Graphical User Interfaces (GUI) sind eine zentrale Schnittstelle zwischen Anwendern und Anwendungen. Aufkommende Ansätze wie Robotic Process Automation (RPA) erlauben eine automatisierte Steuerung dieser Oberflächen, indem Softwareroboter menschliche Interaktionen mit den GUIs simulieren. Diese Interaktionsschritte, wie z. B. das Selektieren und Anklicken eines Buttons, müssen jedoch manuell spezifiziert werden, was sich negativ auf die Akzeptanz des Vorgehens und die Kosten auswirken kann. Um einen weiteren Automatisierungsgrad zu erreichen, müssten Interaktionselemente automatisch identifiziert werden können, um folglich die Ablaufschritte zu generieren.
Bilderkennung hilft bei der automatischen GUI-Analyse
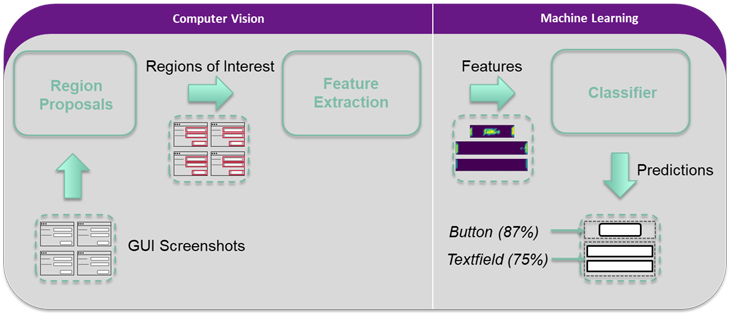
Doch wie lassen sich GUI-Elemente automatisiert identifizieren und welche Herausforderungen treten dabei auf? Natürlich kann der HTML-Code von Web-Anwendungen inspiziert und GUI-Elemente können anhand von Tags oder IDs identifiziert werden. Einen plattformübergreifenden Ansatzpunkt stellen dagegen Screenshots der GUIs dar, sodass sich das Problem in den Kontext der Bilderkennung verlagert. Seit Jahrzehnten eingesetzte Methoden aus dem Bereich des Computer Vision können hier Abhilfe schaffen.Weniger komplexe Verfahren, wie beispielsweise die Kantenerkennung, werden mit komplexeren Ansätzen kombiniert, um Regions of Interest (ROI) zu erkennen, die ein Interaktionselement darstellen können.
Step by Step – So funktioniert die automatische Bilderkennung mithilfe von Computer Vision und Machine Learning
-
Datenakquisition
Wie bei jedem Machine Learning Projekt stellen Daten die Ausgangslage für eine anschließende Untersuchung dar. Hierbei bleibt einem nur die manuelle Suche nach Screenshots von Eingabemasken, wenn nicht bereits Screenshots von internen Anwendungen automatisiert erfasst werden können. Die so gewonnene Datengrundlage kann anschließend mit einem Faktor von n durch Vervielfachung (engl. Data Augmentation) potenziert werden. Permutationen atomarer Bildtransformationen (z. B. Vergrößern oder Verschieben) können so aus einem Ursprungsbild beliebig viele Trainingsdaten erzeugen. -
Extraktion von Regions of Interest
Hier bieten sich unterschiedliche Möglichkeiten. So lassen sich Annahmen treffen, wie z. B. dass jedem Interaktionselement eine Beschriftung vorangeht oder dieses durch vier umrandende Linien definiert wird. Anhand dieser Kriterien können durch Einsatz von CV-Algorithmen Bereiche auf dem Screenshot identifiziert und extrahiert werden. Alternativ können komplexere Verfahren wie Convolutional Neural Networks (CNN) eingesetzt werden. -
Identifikation
Zur Klassifikation, also zur Zuordnung einer konkreten Interaktionselementklasse, wie Button oder Textfeld, kommen Verfahren aus dem Machine Learning zum Einsatz. Hier haben sich vor allem Support Vector Machines (SVM) als Lernalgorithmus bewährt, wenn die Anzahl an Features hoch und die verfügbare Datenmenge gering ist. Aber welche Merkmale lassen sich aus Bildern extrahieren?
Komplexer Ansatz, der erste gute Ergebnisse liefert
Im Gegensatz zu klassischen Data-Mining-Projekten, wo beispielsweise durchschnittliche Prozesslaufzeiten oder andere, weniger komplexe Features zum Trainieren und Anwenden von ML-Modellen verwendet werden, müssen wir hier tiefer in die Trickkiste greifen. Von lokalen Pixelintensitäten hin zu komplexeren bildbeschreibenden Deskriptoren, wie dem Histogram of Oriented Gradients (HOG), gibt es eine Vielzahl an Möglichkeiten. Letzteres beschreibt die Abbildung der Anzahl der Kantenorientierungen innerhalb eines Histogramms. Damit können Ähnlichkeiten zwischen unterschiedlichen Bildern festgestellt werden, ohne die exakten Positionen der Kanten kennen zu müssen. Die so entstehenden Muster werden von einem SVM-Klassifizierer gelernt, um auf dieser Basis zukünftig unbekannte Interaktionselemente zu identifizieren.

Abschließend kann die Kombination aus extrahierter ROI und prognostizierter Interaktionselementklasse als Input für andere Anwendungen, wie beispielsweise einen Softwareroboter, dienen.
Insgesamt zeigt ein bereits umgesetzter Prototyp vielversprechende Ergebnisse, bei denen eine Gesamtgenauigkeit von mehr als 90 % zur Identifikation von Interaktionselementen auf Screenshots erzielt werden kann. So können zukünftig weitere Automatisierungsgrade für Testentwickler erreicht werden.
Hinweis: Dieser Artikel fasst im Wesentlichen Erkenntnisse aus Literatur-Recherche, eigenen Experimenten und Experten-Interviews aus der Masterarbeit von Dave Kaufmann an der FH Münster 2018 zusammen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



